Toolkit Overview : Define : Plan : Gather : Preserve : METADATA : Storytelling : Share : Recommendations
El Grito de Sunset Park Use Case
METADATA MODELING OVERVIEW
INTRODUCTION
This section presents a metadata model for describing videos of policing incidents and misconduct, and outlines our process for developing it. It emerges from a collaborative project between El Grito and WITNESS to review and analyze video and documentation gathered by local groups to understand patterns of police abuse.
This metadata model was not used in the project, but rather comes out of it. It is an abstraction of how information was collected and assembled by the project team, reflecting the way they organized, identified, analyzed, and made connections between the data. This process was iterative, and we learned and adjusted along the way. Check out the Metadata: Getting Started section for more details.
We hope that this model may be useful to other police accountability groups as a structure or basis for their own metadata projects. For example, the metadata model can be used and customized by anyone to create their own database template.
In addition to the metadata model below, the following pages document the model-making process as a kind of “walkthrough” for anyone who wants to develop a metadata model of their own, no matter what human rights issue they are working on or what kind of information they are gathering.
WHAT IS A (META)DATA MODEL?
A data model is a way of showing how types of information are organized and related to each other in a particular context. It is often represented in a graphical way, in a flowchart-like diagram.
“Metadata” is just a specific kind of data. It means “data about other data,” such as data about videos, or data about case files, or data about news articles. In the El Grito project, we were dealing with both “data” and “metadata.
WHAT IS A DATA MODEL FOR?
Just as a blueprint depicts a structure to guide the construction of a building, a data model can serve as the starting point for building a database. All databases have some kind of underlying structure, even if it is very basic, like columns in a spreadsheet.
A good data model:
- Gives you a bird’s-eye-view of what you are collecting data about, helps ensure that you are “solving for the problem.”
- Reduces redundancy (and errors) in data collection / creation / entry.
- Enables you create data that you can work with, analyze, and visualize effectively later on.
- Can be used across multiple organizations working in the same domain so they can easily share information with each other.
WHAT IS A METADATA SCHEMA?
A metadata schema is an overlapping concept to a data model. Like a data model, it serves as a blueprint or plan for how information in a given “space” is structured. While both outline the abstract data entities, their attributes, and the relationships between them, a schema additionally defines rules pertaining to the actual implementation of the data model (like in a database), like the data format, whether the data entry in a field is mandatory or optional, etc.
For this project, we did not go so far as to create a metadata schema. But it is a viable next step beyond this data model, should El Grito or other groups decide to pursue it further.
PROTOTYPE DATABASE TEMPLATE

We prototyped the El Grito data model in Filemaker Pro for testing purposes, and are offering it “as-is” for others to work with and adapt. We can’t warranty that it is error-free. Download available here.
(md5: 8a41b1c18e59cb65f3ff7490397301c9 — what this is)
ERD DRAWING TOOL
![]()
ERDPlus is a free web-based data modeling tool for creating entity-relationship and relationship schema diagrams, which can be exported as image files.
EL GRITO DATA MODEL (DRAFT)
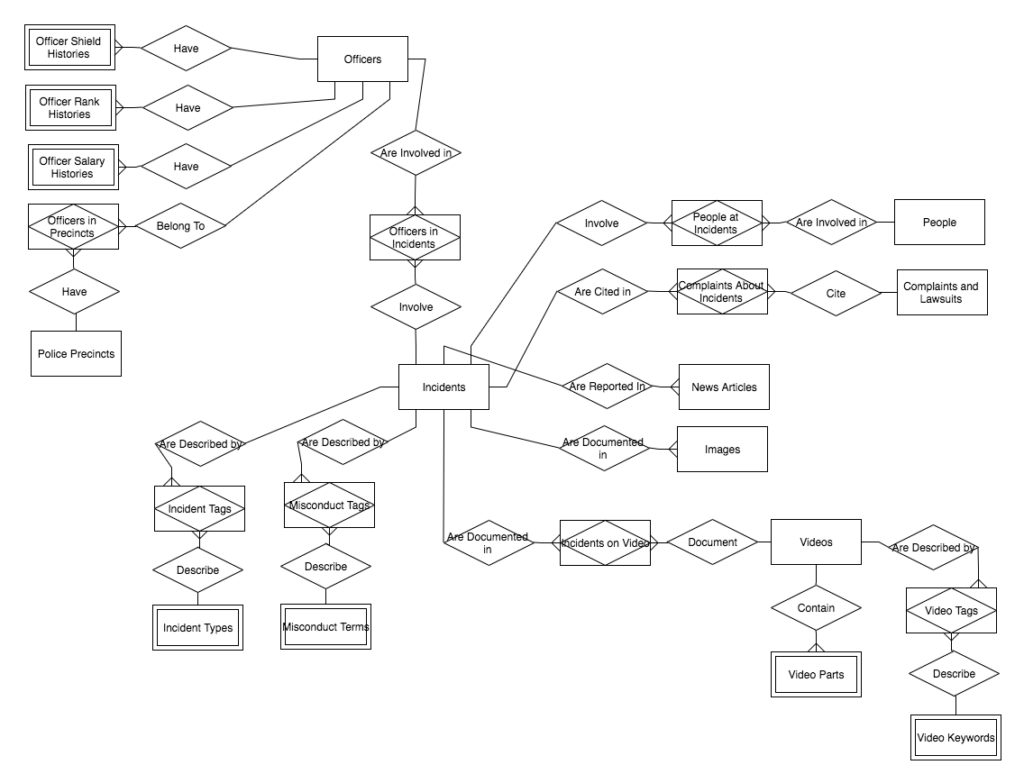
WHAT IS THIS COOL THING?
An Entity Relationship (ER) Diagram is a type of flowchart that illustrates how “entities” such as people, objects or concepts relate to each other within a system.
SOURCE: LucidChart
EL GRITO RELATIONSHIP SCHEMA DIAGRAM (DRAFT)
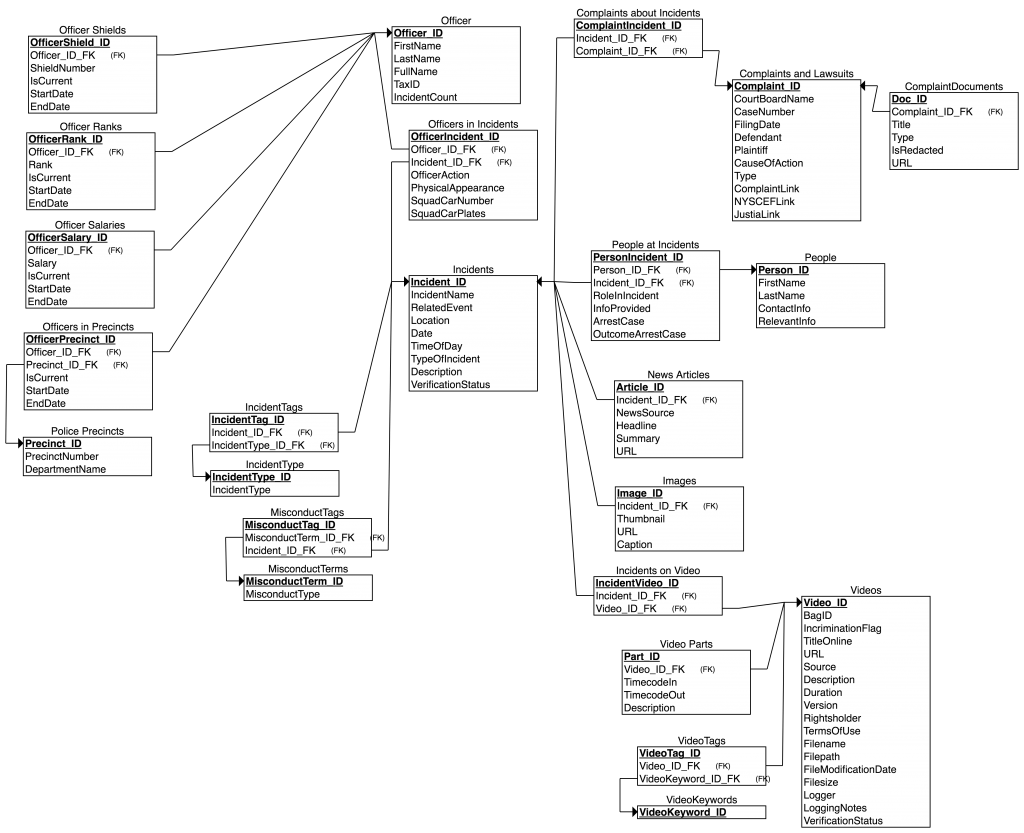
WHAT IS A RELATIONAL DATABASE?
Databases typically use tables, consisting of columns and rows, to store data. A simple database with a single table is sometimes called a “flat file.” A spreadsheet is a familiar kind of flat file.

The limitation of a flat file is that a single table can only store data about one type of thing. For example, a table that stores data about “Officers” and has columns for “First Name,” “Last Name,” and “Shield Number” can’t be effectively used to store data about “Videos” (which do not have first names, last names, or shield numbers). Trying to store data about different types of things (e.g. Officers, Videos) in a single table creates data that is very difficult to sort, analyze, and use.
A relational database addresses this problem. A relational database employs multiple tables that are related to each other by means of “keys” or IDs. Having multiple tables means that a database can store data about multiple types of things, like Officers, Videos, Incidents, etc.

WHAT ABOUT NON-RELATIONAL DATABASES?
There are also newer, non-relational databases (sometimes called “NoSQL” databases) that don’t use tables or pre-defined schema. These are often used in big-data web contexts (e.g. Amazon, Google) where volume and speed are important. HURIDOC’s new Uwazi platform also uses a NoSQL database, which allows users to flexibly create different fields/headings to organize and describe their content.
The data modeling section of this toolkit is written with a relational database in mind, but is applicable to relational and non-relational databases — if using the latter, some of the discussion about associative/weak entities and keys will not be relevant.
BEFORE YOU START
The main question to ask yourself before you create a data model is whether someone else has already done it! If so, and it’s accessible, you can perhaps use or adapt an existing model instead of starting from scratch.
Using a shared data model can make it easier for you to exchange data with others who are working on the same issues. Many communities and sectors publish data models or metadata schema relevant to their work in order to promote and enable this interoperability and exchange. This is one of the main reasons we’re sharing the one we’ve developed above.
When we got started in thinking about the data model for the El Grito project, we looked at examples developed by others working on police accountability, including Berkeley Copwatch, Legal Aid, Open Oversight, and Open Police Complaints. While none of these models were exactly suited to our project, it was still instructive to see how they were conceptualizing the information and what they were tracking. Check out Metadata: Getting Started to find out more about our process.
Besides determining whether you need to develop a new data model, and looking at examples from allies in the field, other prerequisites for developing a good data model include:
- Understanding the purpose of the data, what users will want to do with it.
- Having background knowledge of the content / things that the data describes, and/or the ability to dig into the content.
- Being able to think conceptually about the organization of information.
WALK-THROUGH AT A GLANCE
Here are the basic steps to creating a data model, elaborated in further detail on the following pages:
- Identify the entities you want to describe.
- Identify the attributes you want to capture about each entity.
- Identify the relationships between the entities.
- Test the model in real-life and fix any problems.
- Create a metadata schema and documentation.
It is worth noting that the process doesn’t unfold as neatly and linearly as outlined here. For the sake of clarity, this walkthrough doesn’t jump back and forth between the steps, but in real-life, it’s an iterative trial-and-error process.
TERMINOLOGY
Entities are the things that the database is describing, such as Officers, Incidents, or Videos.
Attributes are the properties of the entities that the database keeps track of. For instance, for Officers, you might have attributes like Name, Badge Number, and Rank.
Relationships are the connections between different entities. For instance, Officers might appear in Videos, or belong to a Police Precinct, or be involved in an Incident.